The bayesian update
Now let's consider a more complex situation.
Scenario
Imagine we're interested in a genetic variant which has two alleles A and B. We sample some chromosomes from a large population and want to use Bayes to estimate the allele frequency.
How does Bayes theorem learn?
How does Bayes theorem update what we should believe? To find out, type your observed alleles (a list of A's and B's) into the Bayesian update-o-meter™ below:
What you are seeing is the bayesian update. With each observation you make, Bayes' theorem computes its new belief (i.e. the posterior distribution) about the frequency of the 'B' allele.
The solid line shows the current posterior. The dashed line shows the posterior one data step before (i.e. before the last observation).
The text on the right shows the posterior mean estimate (that is, the mean of the distribution) - and its mode (most likely value), if it has one. (When are these the same?)
Note
The order of A's and B's does not matter to the posterior, just their number.
Play around with this a little and then try these questions.
Questions
- Press 'reset' data (and/or 'reset prior') or delete the data to get back to the start.
- Add a single 'A' allele observation. What does the posterior look like? What is the 'best guess' allele frequency estimate?
- Delete it and add a single 'B' allele observation instead. What does the posterior look like? What is the 'best guess' allele frequency estimate?
- What if you add two 'B' alleles? Three? How many do you have to be really confident the frequency is 100%?
- Now try adding a mixture of 'A' and 'B' alleles. For example, try four
As and twoBs. What does the posterior look like?
Feel free to play around with this until you understand how the data affects the posterior.
Adding prior information
So far we have not added any prior information. Let's try that now. Reset the data again to get back to the start.
Prior data example
Suppose we already had data on this population - for example, suppose we'd done a pilot experiment and already observed five of each allele.
Model this now by setting 'Prior A' and 'Prior B' to 5 in the boxes underneath the data.
Now you can see that, before we start collecting our new data, we are already reasonably sure that we have an allele frequency somewhere in the middle of the range - although it's still pretty uncertain.
What happens now as we add data (for example, four As and two Bs again)? Is the change in posterior with each
additional data point more, or less dramatic than it was before? (If you press 'reset data' you can see how the inference with prior data compares to the inference without.)
What you are seeing is bayesian shrinkage. The prior information acts to 'shrink' the estimates (and the whole distribution) towards the prior estimate.
Maths explanation
In this scenario it turns out that:
- The likelihood function is a binomial distribution.
Explanation: Suppose the frequency of the 'B' allele is . As we start sampling, we therefore expect to observe a 'B' allele with probabilty - and an 'A' with probability . Let's imagine that the population is so large that our sampling does not affect this frequendcy much. To get the likelihood of any sequence, we therefore just multiply over the alleles drawn - for example
In general, if the sequence has 'A' alleles and 'B' alleles the likelihood is just:
This is the form of a binomial distribution.
(The 'constant' is just here because we switched to thinking of the data as counts instead of the full sequence - we have to count the number of sequences with those counts. The constant doesn't depend on or hold any information about , and so isn't very important.)
The prior is flat. . In this example we have put in no prior information so the prior is
The posterior is a beta distribution. Multiplying the prior and likelihood, and normalising as in Bayes theorem, the posterior is therefore just
If this looks a lot like the likelihood, that's because it is!
A quick glance at the expression for a beta distribution will show you that this is just the form of a beta distribution - in fact it is:
Key point
The only difference here between the likelihood and posterior is in the constant.
The constant in the likelihood is supposed to normalise the distribution over all possible values of data. If the data is the number of 'A' and 'B' alleles in the data, the constant is as shown in the definition of the binomial distribution. (On the other hand, if we think of the whole ordered sequence of A's and B's as the data, the constant is just .) Either way, this term is constant with respect to the frequency so it doesnt really matter what it is - it's just a constant.
On the other hand, the constant in the posterior has the job of normalising the distribution over all possible allele frequencies . This is where knowing the mathematical form of the beta distribution is useful - it can be worked out, and turns out to be
where is a particular function called the beta function. (If you read its definition, you'll see it is, essentially, defined as just the function needed to normalise this distribution.)
Therefore, even though in principle we'd have to work out the normalising constant to figure out the posterior (as we did in the covid example - here it is determined by the maths. Someone has worked it out for us already, how nice of them!
So what happens if we add prior information? Well if we assume the prior is also a beta distribution, say:
then all the maths works out again:
(The normalising constant is again determined as before by the form of the function.)
Note
The beta and binomial distributions have this dual relationship to each other, because they have overlapping mathematical forms. In bayesian stats parlance they are said to be conjugate.
Of course - we could also use a different prior distribution (not a beta distribution). That's not a conceptual problem but the maths won't work out the same way - we might then need numerical integration, or something, to solve it.
In short, you can either think of the inference as processing all the data at once:

...or as processing the data points one at a time:
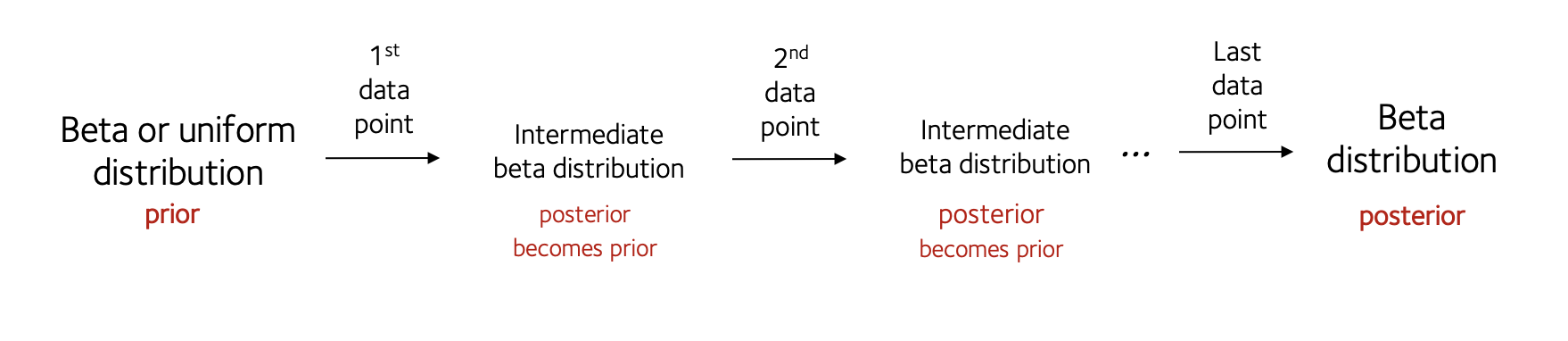
Either way, Bayes theorem gives the same answer.